This project was the second coursework for the Natural Language Understanding, Generation, and Machine Translation (NLU+) course I took as part of my MSc Artificial Intelligence at the University of Edinburgh. The assignment focused on Japanese to English neural machine translation (NMT) and consisted of several parts:
- Understanding the baseline implementation, an encoder-decoder bi-directional long short-term memory network (as implemented in nmt_toolkit).1
- Exploring the model further, looking into things like replacing greedy search with beam search and experimenting with adding more layers.
- Implementing and evaluating the lexical model proposed by Nguyen and Chiang (2017) (Section 4).
Here's the architecture of the model I used for experiments with the lexical model:
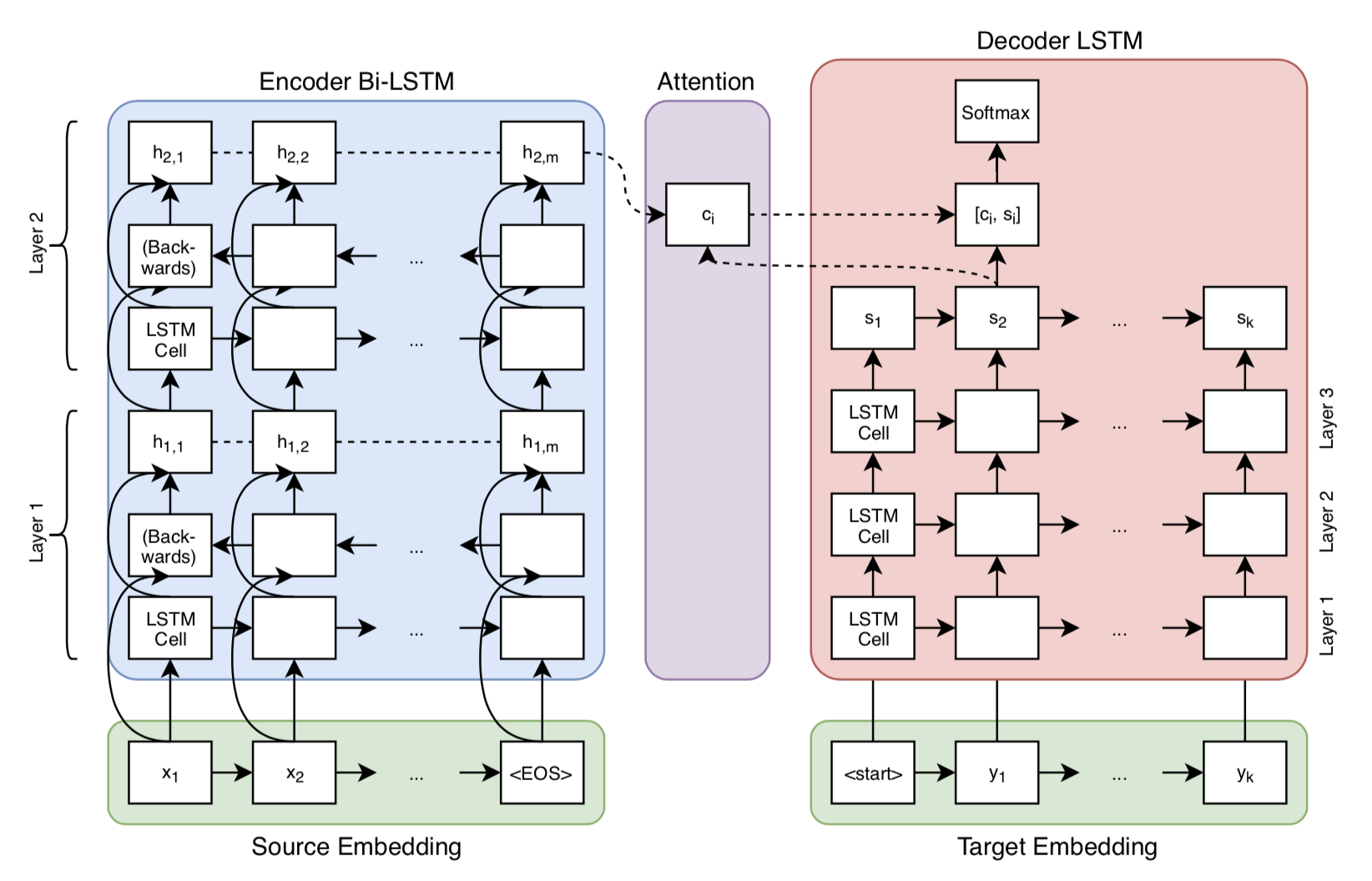
Diagram of the NMT system architecture with a 2-layer encoder (bi- directional LSTMs) and a 3-layer decoder (LSTMs). Figure made in draw.io and adapted from Britz et al. (2017).
The lexical model by Nguyen and Chiang (2017) is meant to improve the translation of rare words. Attention-based NMT systems suffer from the fact that attention takes into account the context of previously translated target words, which means it will sometimes favor words that fit well within the context of the translation so far, but that do not correspond to the source word being translated. The lexical model attempts to solve this by jointly training an extra feed-forward network that generates target words purely based on the source word. See Section 4 of Nguyen and Chiang (2017) for a more detailed explanation.
For the assignment, we used a fraction of the data and computing power generally available to NMT researchers (I trained on my laptop for a few hours instead of many GPUs for two weeks), so the results were not very good in an absolute sense compared to the state of the art (order of ~30 BLEU). In the relative sense, though, my implementation of the lexical model improved the NMT system's performance significantly: the BLEU score went from 7.98 to 10.90 and perplexity went from 22.4 to 20.0.
You can check out my code on GitHub: leonoverweel/infr-1157-nlu. My full report, with much more analysis, is available here and embedded below:
I did this part together with a partner, before we both continued on our own. ↩︎