This was the open-ended second semester group project for the Machine Learning Practical (MLP) course I took as part of my MSc Artificial Intelligence at the University of Edinburgh. I worked with Marius Urbonas and Martynas Grigonis to train a reinforcement learning agent to solve text-based games in Microsoft's TextWorld environment.
We wrote a report titled “An Exploration of Count-Based Exploration Methods in Text-Based Games” on our project, with the following abstract:
Teaching a reinforcement learning agent to solve text-based games is a challenging task. Actions in text-based games are free-form textual commands constructed out of a large dictionary of words, leading to an immense action space. In addition, the environment provides the agent only with sparse rewards in the form of game wins or losses, making it difficult to find winning policies. In this situation, a simple epsilon-greedy policy with epsilon annealing is not sufficient to encourage enough targeted exploration of the state and action spaces. Therefore, more effective exploration mechanisms are required to aid the discovery of optimal policies for the agent, which allow it to solve the game. We propose a reinforcement learning agent for the text-based game environment with an episodic counting-based exploration mechanism which helps it to discover action sequences that yield the final reward more quickly. We compare our mechanism with other counting-based exploration mechanisms, which, to the best of our knowledge, have not been applied to text-based game environments with comparably large action spaces. Because of the extensive compute time required to run our experiments, we are unable to make definite conclusions about the effectiveness of our proposed agent. However, initial results look promising.
We built our experiments on top of the Long-Short-Term-Memory Deep-Q-Network (LSTM-DQN) architecture proposed by Narasimhan et al. (2015) and extend it with five different strategies to improve exploration of the vast natural-language action space typical to text-based games:
- DQN-S+: a cumulative state counting approach that discounts the value of previously-visited states, as proposed by Yuan et al. (2018).
- DQN-S++: an episodic version of state counting, also proposed by Yuan et al. (2018).
- DQN-MBIE-EB: a model-based interval estimation exploration bonus, as proposed by Strehl and Littman (2008).
- DQN-UCB-SA: an upper-confidence bound state-action counting approach, also proposed by Strehl and Littman (2008).
- DQN-KM++: our novel approach, an episodic k-means clustered counting bonus, inspired by Abel et al. (2016).
We experimented with changing the length of the quest the agent had to complete to see which approach was best able to deal with the larger action spaces of longer quests. Our code is available on GitHub. Although computational restrictions did not allow us to run enough experiments to get our error bars small enough to make any definitive conclusions, initial results for our novel approach, DQN-KM++, looked promising:
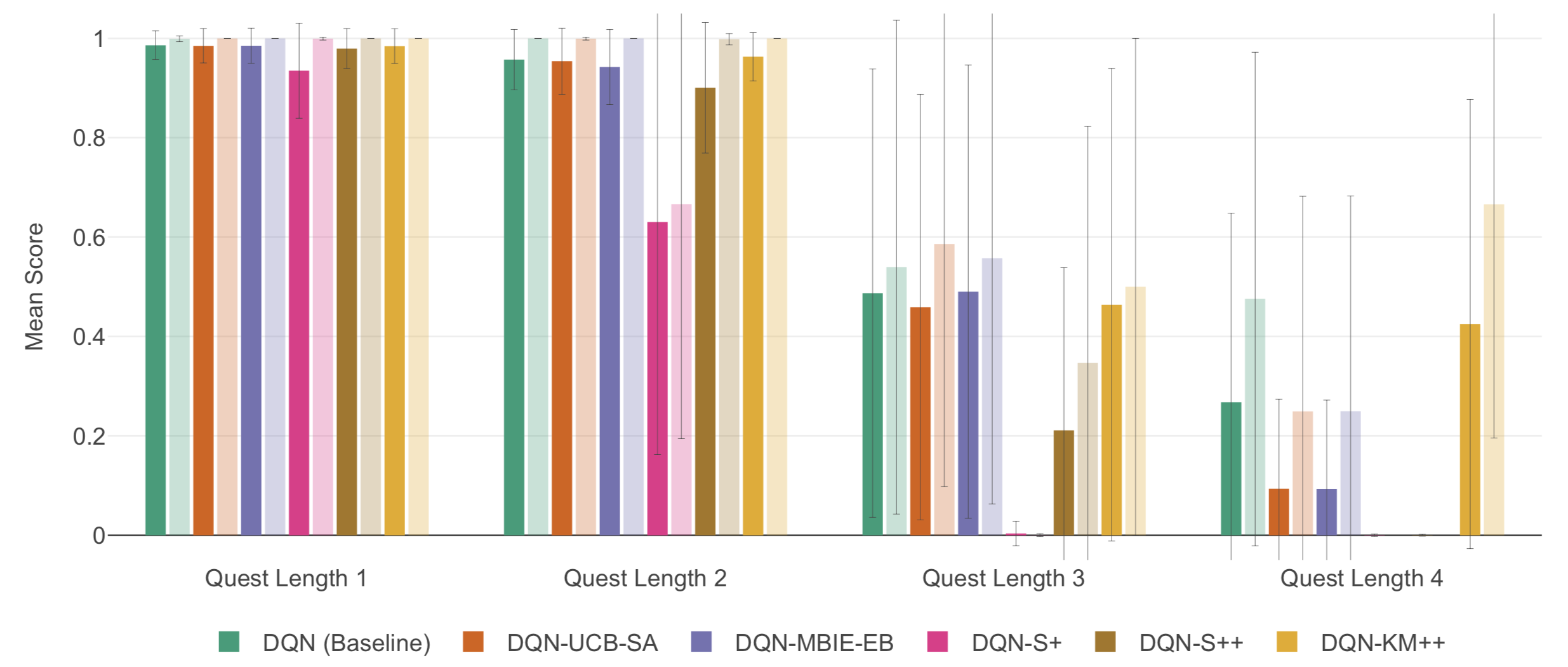
Mean scores with error bounds for our different models trained on games with quest lengths 1 through 4. Darker-shade bars represent means over the full 400 episodes; lighter-shade bars represent means over the last 50 episodes.
For a much more in-depth explanation of our project and our results, please see our report below (or download it as PDF):